Как понять, где слонику стало тяжело
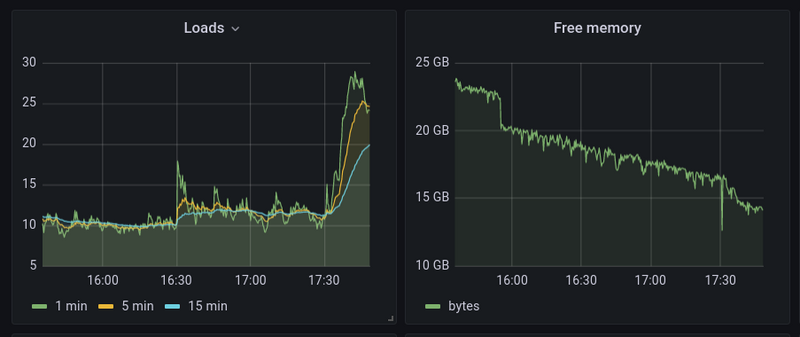
На работе столкнулся с проблемой - судя по мониторингу резко начинает расти load average, причём увеличивается количество форков postgres и суммарная нагрузка на CPU, которую потребляет postgres начинает зашкаливать...
htop показал, что есть десяток процессов постгреса, каждый из которых кушает почти 100% от ядра (точнее от потока - здравствуй, hyperthreading, дальше буду просто писать - ядро). Долго пытался разобраться с тем, как оперативно ловить такое, в итоге выродил скрипт со следующей простой логикой:
- Получаем список процессов postgres, оставляем те, что потребляют более 95% CPU, сортируем по нагрузке.
- Пробегаем по PIDам данных процессов для каждого из которых вытряхиваем из базы выполняемый ими в текущий момент запрос и выводим PID и запрос.
#!/bin/sh
for pid in `ps -eo pid,comm,pcpu | sort -n -k 3 -r | awk '$2~/^postgres$/ && $3>95 { print $1 }'`; do
echo "\nPID: $pid\n"
sudo -u postgres psql -X -A -w -t -c "select query from pg_stat_activity where pid = $pid;"
done
3 строки смысловой нагрузки и полные штаны счастья! Затем дёргаем несколько раз данный скрипт и обнаруживаем, что из 11-ти процессов postgres 10 выполняют один и тот же запрос. И более того, эти форки никак не закроются, т.е. могут часами висеть на этом запросе, сжирая в общей сложности 10 потоков CPU из 32х возможных и 40Gb оперативной памяти.
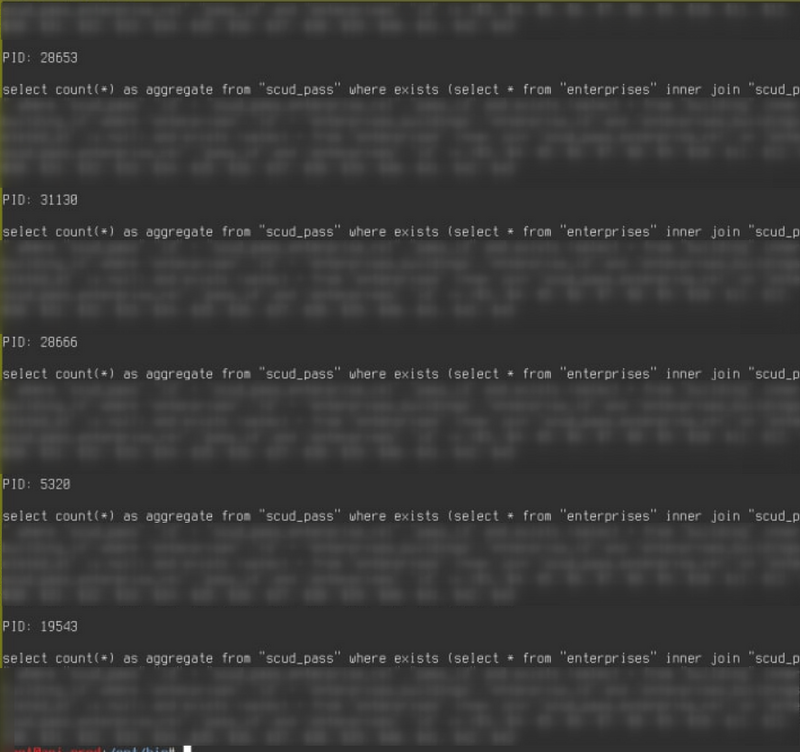
Далее отправляемся к разработчикам разбираться что это за чудо чудное и диво дивное. Выясняется, что при запуске ручками запрос отрабатывает за полсекунды, но никак не висит 3 часа, а в такое состояние его приводит стечение обстоятельств, которое в этой статье осветить не получится, да и не нужно. Одним словом, запрос вроде как починили, но на всякий случай, чтобы ночью спать спокойно, прикручиваем в крон раз в минуту костыль, который будет с помощью этого скрипта убивать по маске все подобные запросы:
kill -9 `/path/to/highloadsql | grep -B 3 -F 'as aggregate from "scud_pass" where exists' | grep '^PID:' | cut -d " " -f 2 | xargs`
Всем добра и низкого loadavg.